Adobe VoCo, el "photoshop del audio" que agrega y cambia palabras de cualquier voz grabada
Si nos detenemos a analizar las posibilidades de edición de audio, en muchos sentidos ya contamos con herramientas equivalentes a lo que sería Photoshop para fotografías pero en términos de audio, pudiendo retocar, modificar, combinar, filtrar y procesar de muchas maneras el material de audio. Sin embargo, aún queda un largo trecho cuando se trata de procesos de resíntesis de material que sean suficientemente fieles a las muestras crudas.
En su reciente conferencia MAX, la gente de Adobe, responsable de piezas populares de software como Photoshop, Illustrator y Audition, ha presentado lo que consideran un “photoshop para audio”, al menos en términos de la grabación de voces, como comentó el desarrollador Zeyu Jin en la presentación del llamado proyecto VoCo, un algoritmo que, sin afirmar si llegará a estar disponible comercialmente, presentó con algunos ejemplos interesantes.
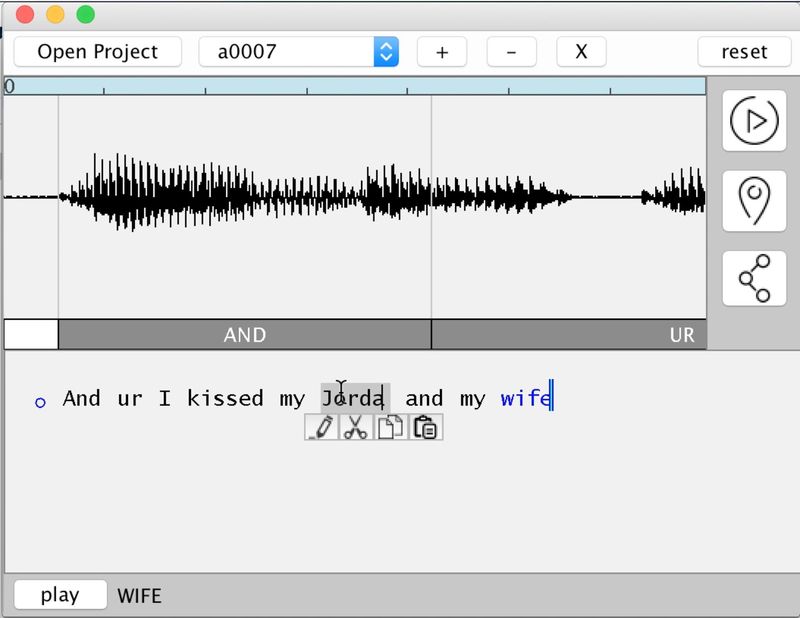
Se trata de un agregado de Adobe Audition desarrollado por miembros del equipo de investigación de la compañía y la Universidad de Princeton. El software se basa en un sistema de resíntesis que permite editar y agregar palabras a un determinado discurso, pudiendo (re)sintetizar la voz registrada. En la presentación por ejemplo, se puede apreciar como en una frase donde dice “besó a sus perros y su mujer” intercambia los sustantivos desde texto, luego agrega la palabra “jordan” en vez de “mujer” y posteriormente agrega material que no incluye la grabación, “tres veces”.
Aunque en el comunicado oficial de Adobe se habla de la posibilidad de “cambiar o insertar una o varias palabras en grabaciones de doblaje, diálogo y narración” debido a errores o cambios necesarios, es claro que una tecnología de estas puede tener muchos usos, algunos de ellos quizás no muy benéficos cuando se trata de asuntos políticos, material de evidencia, entre otros, para los cuales no es de extrañar que ya existan tecnologías similares. De hecho en su presentación se menciona que ha sido más fácil lograr el algoritmo que hacer que el sistema tenga una especie de función de marca de agua de tal forma que se detecte cuando fue hecho así, en caso de que pueda caer en manos equivocadas.
Sin embargo, más allá de nuestras conspiraciones y los interrogantes éticos que de un software así puedan desprenderse, es importante destacar lo mucho que se acerca el algoritmo a la síntesis de una voz tan similar a la identificada en el discurso. Para ello, según comentan los de Adobe, es necesario tener al menos 20 minutos de grabación de una voz, de tal forma que se pueda analizar el material lo suficiente como para recrearla en otras palabras.
Como el mismo Zeyu Jin comentó en la conferencia, su idea es generar en el audio una revolución similar a la que causaron con Photoshop en términos de la fotografía. No se sabe si VoCo es apenas el comienzo de otras herramientas similares, pero es claro que tienen al menos algo de interés en el audio, por lo que será cuestión de tiempo conocer lo que se traen entre manos. Por lo pronto, no se tiene más información sobre VoCo.
Miguel es un investigador que relaciona la filosofía, el arte, el diseño y la tecnología del sonido. Vive en Medellín (Colombia) y es fundador de varios proyectos relacionados con lo sonoro, como Éter Lab, Sonic Field y Designing Sound.








