Presión sonora y sonoridad (III): curvas isofónicas (Fletcher-Munson) y de ponderación (A, B, C, K)
- Niveles típicos de presión sonora (SPL)
- Enmascaramiento temporal: ¿viva la novedad?
- Curvas isofónicas de Fletcher-Munson
- Algunas conclusiones a partir de las curvas isofónicas
- Otras curvas isofónicas
- Curvas de ponderación A, B y C: hecha la ley, hecha la trampa
- Los db..(A), db..(B), db..(C), dB..(K)
Habíamos dejado a propósito pendiente entrar un poco más en detalle en cómo la percepción del nivel audio es dependiente del tipo de contenido, es decir, de cómo sea la propia señal. No se perciben igual de fuertes señales del mismo nivel de energía pero que ocupen diferentes frecuencias, que tengan diferente reparto de la energía por las distintas zonas del espectro. Es más difícil oír los extremos (graves y agudos) que los medios. Nos generan una sensación de menor intensidad aunque se trate del mismo nivel de presión sonora (SPL).
Niveles típicos de presión sonora (SPL)
[Índice]Y es que el nivel de presión sonora (SPL) mide realmente una característica física, no el cómo sentimos, a pesar de que muchas figuras y textos, leídos superficialmente, puedan llevarnos a pensar otra cosa.
El nivel 0 dBSPL corresponde a una presión sonora de 0,00002 Pa, que se suele considerar el umbral de audición pero que sólo lo es para señales que no residan en los extremos audio, sino en las octavas centrales (concretamente ese es el umbral a 1kHz). De forma parecida el nivel 120dBSPL suele considerarse un umbral de dolor (de nuevo para 1 kHz).
Los muchísimos gráficos y tablas (como la que aparece a continuación) que asocian a cada nivel SPL algún evento sonoro de la vida cotidiana contribuyen a extender ese mito de que el SPL mide de forma muy paralela a cómo oímos. Pero no es así. Mide, en el fondo, la presión sonora en el aire, no nuestra forma de sentir esa presión.
| Fuente | Presión sonora (Pa) | dBSPL |
| Cohete | 100000 | 195 |
| Junto al reactor de un avión | 6300 | 170 |
| Avión a reactor grande | 2000 | 160 |
| Avión a reactor medio | 630 | 150 |
| Avión a hélice | 200 | 140 |
| Golpe en tutti de orquesta con 80 músicos | 63 | 130 |
| Martillo neumático | 20 | 120 |
| Gran sistema de ventilación | 6.3 | 110 |
| Autopista, imprenta | 2 | 100 |
| Camión pesado a 6 metros, manifestación con griterío | 0.63 | 90 |
| Calle con tráfico intenso, oficina ruidosa | 0.2 | 80 |
| Equipo audio doméstico | 0.063 | 70 |
| Conversación (a 1 metro) | 0.02 | 60 |
| Zona urbana tranquila, de día | 0.0063 | 50 |
| Zona urbana tranquila, de noche | 0.002 | 40 |
| Habla a muy bajo nivel | 0.00063 | 30 |
| Ruido en un estudio de grabación | 0.0002 | 20 |
| Persona susurrando débilmente | 0.000063 | 10 |
|
Umbral de audición |
0.00002 | 0 |
Tened en cuenta que esta tabla es toda ella muy 'ficticia' -como cualquiera parecida- y sólo al efecto de dar una idea de rangos
Este carácter sólo aproximado no resta utilidad a que tengamos en la memoria alguna correspondencia de este tipo para los valores SPL, aunque sí relativiza su valor. De hecho no suenan igual de fuertes todos los camiones ni aeronaves, habría que considerar también a qué distancia estamos de esas fuentes, etc. Está claro que son referencias sólo ilustrativas.
Además, y eso es de lo que nos vamos a ocupar hoy: cómo en función de la propia estructura de la señal se afecta al nivel percibido.
Enmascaramiento temporal: ¿viva la novedad?
[Índice]Por empezar con algo que no está en el título de hoy, un ejemplo claro de dependencia de la escucha con la propia señal son los fenómenos de enmascaramiento temporal. Lo que escuchamos viene influenciado por lo lo que hemos escuchado inmediatamente antes. Fenómenos que por otra parte son comunes al resto de los sentidos. El mal olor de una cloaca lo es menos si llevamos en ese ambiente unos minutos, nos acomodamos a lo que nos ofrece el entorno y pierde protagonismo en nuestra percepción para dejar hueco a recibir nuevos estímulos (que quizá apunten a la llegada de algún nuevo peligro). De forma parecida un sonido estático que se mantiene largo tiempo puede ser molesto pero muchas veces acaba pudiendo ser obviado.
Un ruido estático es menos notorio que un ruido variante que está constantemente reclamando atención sobre su evolución, hasta el punto de aparentar menor nivel. Y no es igual de molesto ese sonido estático si se trata de ruido blanco (muchas veces admisible, al menos a bajo nivel) o si es una interferencia tonal o señal cíclica (bastante incordiante aunque haya presencia de otras señales mucho más fuertes).
Pero por fenómenos de enmascaramiento también nos referimos a otros que actúan en sentido contrario, que en lugar de apoyar ‘lo novedoso’, parecen dispuestos a ‘tapar’ la novedad. Por ejemplo la presencia de un sonido fuerte puede hacer menos audibles los sonidos débiles que vienen inmediatamente detrás, siempre y cuando no sean sonidos muy diferentes sino que ofrezcan una configuración espectral parecida (de otra forma el efecto 'novedad' dominaría en su percepción).
Una de las razones es que la forma de poder atender en el oído al enorme rango de unos 120dB que separa los sonidos más débiles y los más fuertes pasa por contar con mecanismos que ‘endurecen’ la audición ante grandes presiones. La cadena de huesecillos que en un ambiente sonoro tranquilo está relajada y es muy sensible, en cierta manera se ‘previene’ con la llegada de niveles fuertes y dificulta la transmisión para protegerse. En una escala de tiempo mayor, también cuando pasamos un rato largo en un ambiente de fuerte presión sonora, como una actuación de música pop/rock o una discoteca, la capacidad de escuchar se queda trastornada y tarda en recuperar su sensibilidad normal.
Pero en esos efectos de enmascaramiento, especialmente cuando se trata de escalas temporales cortas, hay mucha intervención también de cómo el cerebro interpreta los estímulos que el oído le envía. Por ejemplo un sonido ‘fuerte’ tras uno débil puede hacer parecer más corto el primero. Hay un sinfín de ilusiones sonoras de este tipo que nos hablan del papel esencial de la parte ‘interpretativa/cerebral’ en la audición.
Más allá de juegos de laboratorio con señales muy atípicas que provocan esas ilusiones sonoras, lo más normal es que el enmascaramiento suceda de forma que lo pasado puede enmascarar lo futuro, y sólo en mucho menor medida al revés.
Por ejemplo estamos acostumbrados a oír los sonidos en entornos que reverberan en mayor o menor medida y por tanto que haya ‘colas’ en las que el sonido se amortigua al parar de producirse es algo esperado y que no llama la atención. Pero cualquier fenómeno de tipo ‘pre-eco’ resulta ser por comparación muy llamativo, capaz de alterar el carácter y nitidez de una señal mucho más que un post-eco. Lo mencionamos ahora porque más adelante tendremos ocasión de ver que hay sistemas que al tratar señales acaban generando algunas dosis de pre-eco.
No ahondaremos más sobre estas cuestiones de enmascaramiento temporal, porque nuestro interés principal hoy está en presentar cómo percibimos la sonoridad en función de la frecuencia, algo estudiado hace ya larguísimo tiempo por Fletcher y Munson.
Curvas isofónicas de Fletcher-Munson
[Índice]Fletcher y Munson estudiaron estadísticamente cómo oímos a diferentes frecuencias, a base de anotar las respuestas de un amplio grupo de personas antes señales de prueba. Es muy fácil apreciar que oír dos tonos diferentes con el mismo nivel SPL, como por ejemplo 200 y 1600 Hz, produce sensación de un nivel percibido muy diferente (mucho mayor en el de 1600).
Tuvieron la idea de crear unas ‘gráficas de igual sonoridad’ (curvas isofónicas) para diferentes niveles, desde muy cercanos al umbral de audición a otros ya realmente fuertes. Cada curva representa el nivel de presión sonora (SPL) que hay que producir a cada frecuencia para conseguir una misma sensación que la que se tiene con un determinado nivel a 1kHz. Tomando como referencia el recorrido entre los umbrales de audición y dolor a 1kHz (0 y 120 dBSPL) crearon curvas cada de sonoridad igual a un tono de 1kHz y nivel 0, 10, 20, 30, … etc dBSPL. Las curvas provienen de promediar las respuestas en tests de un amplio grupo de personas.
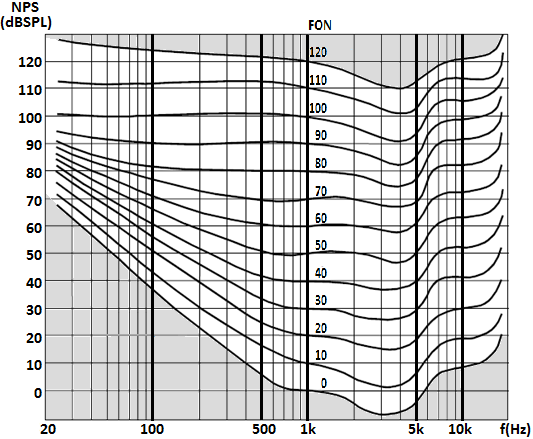
Las curvas Fletcher-Munson son un clásico, y aunque estudios más recientes revelan algunas diferencias, las tendencias que marcan siguen siendo válidas. Así que centrémonos en entender qué información útil nos proporcionan.
Algunas conclusiones a partir de las curvas isofónicas
[Índice]- Desde 1500 hasta 6000 Hz, aprox. , tenemos mayor sensibilidad, con 3000 Hz. como la frecuencia más sensible.
- Salvando esa zona siempre un poco más sensible, por debajo de 600 y por encima de 6000Hz tenemos cada vez más dificultad para escuchar, tenemos menor sensibilidad
- En la parte alta (más de 6000Hz) se trata principalmente de un ‘escalón’ (con unos 10dB menos de sensibilidad que a 1000Hz.) acompañado del efecto de desaparición progresiva de la escucha de los muy agudos (15000 en adelante) que es muy severo. Pero globalmente el recorrido dinámico (salvo en esas altísimas frecuencias que ya se pierden) apenas se ha reducido, siendo de unos 110 dB en vez de 120
- En la parte de bajas frecuencias tenemos efectos mucho más severos, con una compresión progresiva del rango dinámico que llega a ser de sólo 60 dB (la mitad) frente a los 120 presentes a 1000Hz.
- Esa compresión del rango dinámico de los graves se produce sin apenas variar el nivel de dolor: todo se concentra en una pérdida de capacidad de escuchar que eleva los umbrales de audición a esas frecuencias y compacta todas las curvas acercándolas, haciendo por tanto que en esas regiones graves los ‘saltos’ de potencia necesarios para incrementar la presencia de sonido percibida sean menores de lo que cabría esperar (hablo de los ‘saltos’, porque los niveles absolutos son siempre mucho mayores).
- Conviene destacar también el que la parte de altos niveles es, comparativamente, mucho más ‘plana’, con una sensación mucho más ‘equilibrada’ en el sentido de que corra pareja al nivel de presión sonora sin demasiados altibajos según se trate de unas u otras frecuencias.
Podéis pensar en cómo reexpresar esas observaciones en conclusiones útiles.
Estas curvas son las que están, por ejemplo, detrás de los circuitos ‘loudness’ de muchos sistemas hifi y car-audio. Hay distintas versiones (más avanzadas y menos) pero en los buenos se imparte un refuerzo en graves y en agudos sólo cuando estamos reproduciendo a niveles medios y bajos, pero ese retoque no se aplica cuando estamos reproduciendo a niveles altos. Eso facilita la escucha ‘equilibrada’ a cualquier nivel, y nos permite escuchar ‘mejor’ sin necesidad de tener que subir el volumen para poder oír los graves y agudos.
Las implicaciones que subyacen en estas curvas impactan también en muchas decisiones que hemos de tomar, por ejemplo sobre a qué niveles conviene mezclar o trabajar en edición audio. Mezclando a niveles más bajos de los que vayan a ser los niveles de escucha que usen los destinatarios finales, percibiremos reforzados los medios (tendremos mayor sensibilidad a esa zona). Eso podría significar (si no lo tenemos en cuenta) que una mezcla aparentemente equilibrada y biensonante a nuestro nivel de escucha durante la mezcla, suene para los que lo escuchen a niveles mayores desequilibrada con una significativa carencia de medios. No creo que nadie (tampoco yo) os recomiende usar en esos casos el ‘loudness’ al que antes me refería, porque es una escucha engañosa. El preferible oír mal pero con defectos conocidos, y lo del ‘loudness’ es, las más de las veces, un terreno de magia poco confiable.
Como no sabemos a qué nivel se va a escuchar por el destinatario final (a veces sí, si se trata de cine, ferias, instalaciones audivisuales, etc.), tiene este problema difícil solución. Incluso si supiéramos a qué nivel se van a oír nuestras producciones, seguramente no desearíamos pasar horas y horas de trabajo a unos niveles tan altos como los que se estilan hoy día (en cines, clubs, o incluso por los particulares con sus MP3 y auriculares). De ahí la importancia de aprender a escuchar a distintos niveles durante una producción. Personalmente, me gusta ser respetuoso con mis oídos y no trabajar a niveles fuertes, tiendo a buscar la escucha a niveles más bien bajos. Pero de cuando en cuando hay que oír cómo van los resultados a otros niveles más altos para no perder perspectiva.
Una persona entrenada puede ‘aprender’ esas diferencias y le bastará escuchar sólo ocasionalmente a niveles medios/altos para quedarse con una huella en su memoria de cómo están sonando las cosas, Huella que le permitirá seguir trabajando, a unos niveles menores, sabiendo qué tipo de compensaciones tiene que ir realizando.
Además es una sana costumbre esa de ‘refrescar’ el oído con cambios, para que no se acomode a oír siempre de una misma manera y se mantenga atento. Esa es la razón de que de vez en cuando, durante una sesión de trabajo, debamos escuchar otras cosas: grabaciones en ese mismo tipo de estilo/producto (para tener referencias de cómo ha de sonar muestro resultado), o incluso escucha de sonidos que nada tengan que ver para una cierta ‘limpieza’ regular del oído (por ejemplo a mí me gustan especialmente a este respecto buenas grabaciones de sonidos de costa con el romper de las olas tan generoso en ancho de banda y en imagen estéreo). Pero es también beneficioso realizar cambios de nivel en la escucha del material que estamos trabajando.
Tenéis algunos consejos más e interpretaciones prácticas del significado de estas curvas, cara a la sonorización en vivo (algo bien diferente a la cuestión de la mezcla) en: https://www.hispasonic.com/reportajes/jugando-psicoacustica-ii-fletcher-munson/40662
Pero sobre todo lo que debéis es recordar las tendencias principales a las que estas curvas apuntan, para estar prevenidos y saber compensar cuando se necesite ese comportamiento auditivo inevitable.
Otras curvas isofónicas
[Índice]Por más que conocidas, las de Fletcher y Munson (creadas en la década de 1930) no son las únicas curvas de este tipo que existen. Ha habido otros muchos tests con sus propias conclusiones (como los de Robertson y Datson en los años 1950, que diferían bastante, pero que han sido posterioremente desaconsejadas) e incluso se han estandarizado en normas ISO diferentes versiones de curvas isofónicas a lo largo del tiempo.
La propia ISO redefinió sus curvas isofónicas en 2003, y en este gráfico podéis observar una comparativa entre las curvas de Fletcher-Munson (en azul) y las definidas por ISO (en rojo, y extendidas por estimación en línea de puntos).
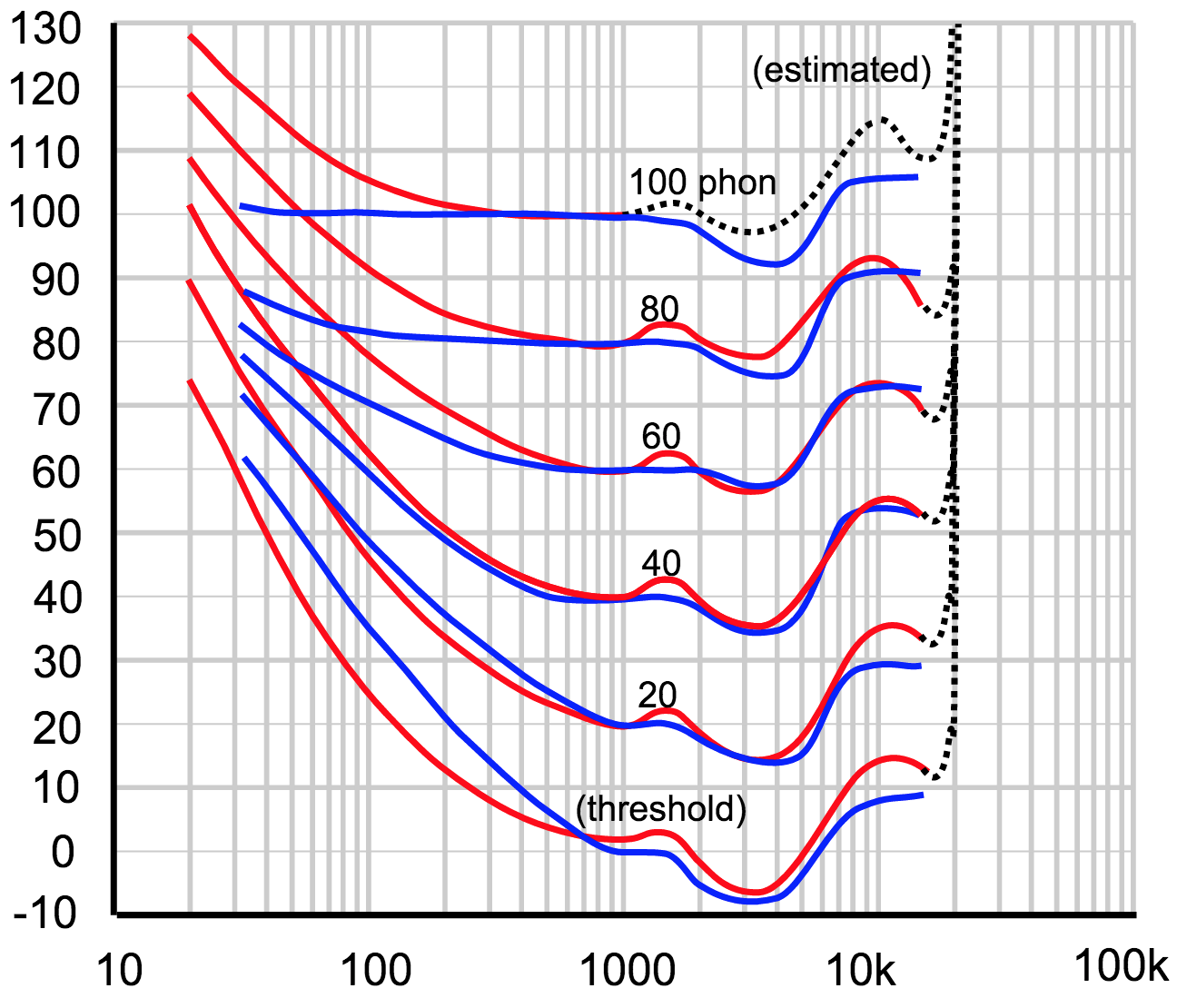
Si tomamos las curvas de la norma ISO 226:2003 como buenas (más recientes, con mejores medios para los tests, etc.), hay diferencias significativas especialmente en la zona siempre crítica de los graves. Fijaos que las curvas ISO apuntan a una reducción aún mayor del margen dinámico respecto al que señalaban Fletcher-Munson.
Curvas de ponderación A, B y C: hecha la ley, hecha la trampa
[Índice]Como respuesta técnica al problema al que apuntan las curvas isofónicas, se han definido unas curvas en frecuencia que, usadas como filtro delante de un equipo de medida o representación (que por sí mismo es mucho más ‘plano’ es su respuesta y no tiene esas diferencias a las que apuntan las isofónicas) hacen que la señal que llegue al sistema de medición/representación venga coloreada de forma parecida a como estaría coloreando nuestra percepción. Curvas que 'imitan' la forma en la que sentimos el nivel de los sonidos con el objetivo de poder ofrecer mediciones que sean algo más útiles que la medida directa sobre la señal original.
Más que definirse por una extrema fidelidad a los contornos isofónicos, se ha pretendido con ellas un filtrado sencillo y fácil de realizar, que sólo aproxime las tendencias principales en las curvas isofónicas, las cuales, al fin y al cabo son sólo un promedio estadístico de lo que cada uno de nosotros percibe.
Son tres curvas definidas en la norma ANSI S1.4-1971 y pensadas para aplicarlas a diferentes ‘intensidades’ de señal. Grosso modo, la curva A invierte la curva isofónica de 40 fons, la B correspondería a 70 fons y la C a 100 fons. Típicamente la que más se usa es la A, que por ser la que se aplica para niveles más pequeños es la que impacta más fuertemente en el resultado (es la que tiene una acción de filtrado más decidida).
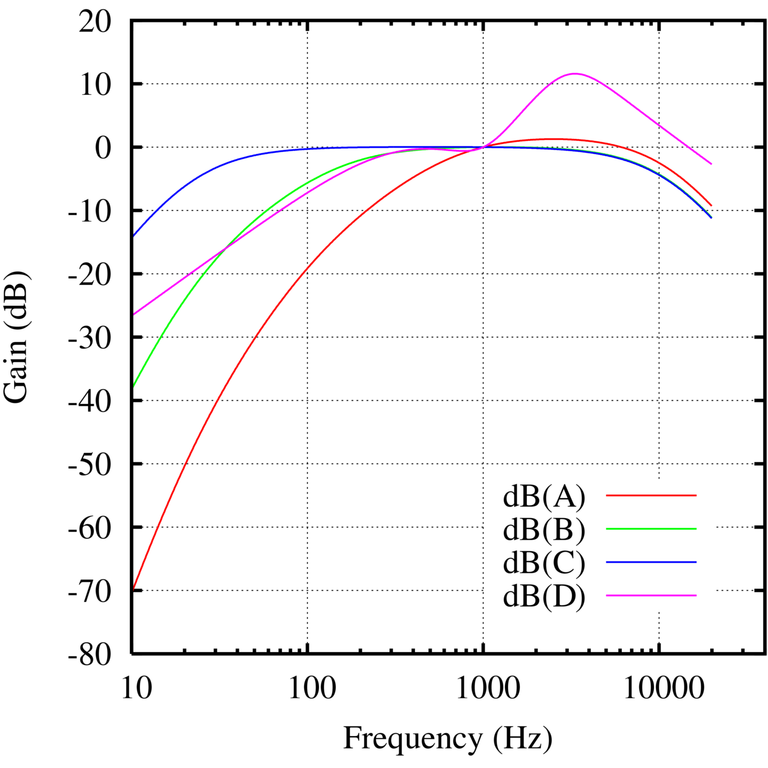
La curva A se usa cuando el sonido que se analiza va a estar presente a niveles bajos, en los que la escucha tiene una enorme pérdida gradual hacia los graves y una bajada de unos 10 en agudos. Sería habitual aplicarla al medir un ruido ambiente o un ruido de fondo en un equipo electrónico, porque se trata de ruidos típicamente de poco nivel. La medida física en dBSPL resultaría más alta de la sensación que tendríamos en FONS, y la aplicación de la curva A intenta paliar eso.
La curva B se aplica al estudiar señales que tienen niveles medios, y es habitual para medir contenidos musicales, por ejemplo. Mantiene un rebaje de la zona grave pero no tan profundo como la A.
La curva C se aplica para señales fuertes, y es la más plana de las tres.
Hay también una curva D que sólo se aplica ante ruidos realmente feroces, como los de aeronáutica y que respecto a las otras destaca porque enfatiza la parte de altas frecuencias.
Una crítica general a todas estas curvas es que han sido obtenidas a partir de señales de prueba sinusoidales, que son muy diferentes a las señales que típicamente se manejan en audio. Como respuesta ha habido otras muchas propuestas de sistemas y curvas de ponderación desde la ISO, EBU y otras entidades.
Más recientemente ha surgido también la curva K, de uso en en ITU BS.1770 y EBU R-128, que introduce una caída en graves (mediante un filtro paso alto) y un refuerzo en agudos (mediante un filtro de tipo escalón o shelving).
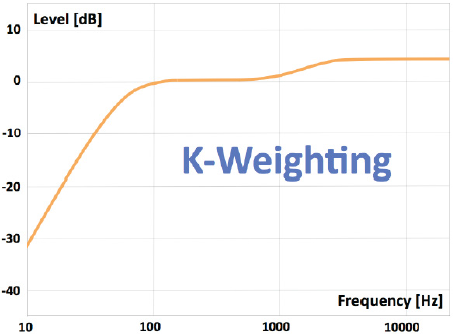
Por contraste con estas curvas, a veces se habla de curva Z para referirse a una respuesta plana entre 10 Hz y 20 kHz (sin ninguna ponderación).
Los db..(A), db..(B), db..(C), dB..(K)
[Índice]La aplicación de las curvas puede hacerse ante muchos tipos de medición, no sólo de nivel de presión sonora, sino también en las señales eléctricas que entran o salen de un equipo, el ruido de fondo que este genera, etc.
En caso de aplicarse alguna de estas curvas, la unidad correspondiente (típicamente algún tipo de dB-algo, como dBSPL en presión sonora, o dBV o dBu en el caso de señales audio eléctricas) se acompaña de A, B o C entre paréntesis dando lugar a cosas como dBSPL(A), dBSPL(B), dBSPL(C), dBV(B), etc. Es importante recordar lo que esto implica en la medida cuando veamos cifras señaladas de esta forma.
Por ejemplo, muchos fabricantes aplican en ciertos tipos de medida la ley A porque el resultado que se obtiene (con un valor menor al ser la que más reduce la presencia de componentes graves) les resulta beneficioso, por ejemplo con una cifra de ruido que aparenta ser menor. No es ningún intento de engaño, si estamos convenientemente informados de lo que esto representa. Otras veces veremos que nos ofrecen las mediciones con y sin ponderación, lo que resulta mucho más transparente.
De hecho ha habido y hay un cierto abuso (incluso exigido en algunas normas) de la ley A, que acaba siendo aplicada a todo tipo de mediciones aunque se trate de señales fuertes.
Otras siglas se han ido generando que tienen su propio significado. Así por ejemplo en digital podremos encontrar LKFS (referido a loudness k-weighted full scale), una escala en dB definida en ITU BS.1770, y que la EBU R-128 denomina LUFS (loudness units full scale). En otro momento podremos presentar R-128 con algo más de detenimiento, pero podéis encontrar también muchas aclaraciones a partir de este enlace de tcelectronic.com o, si no os asustan lecturas más técnicas y menos divulgativas, directamente en los propios documentos de la EBU.

Pablo no puede callar cuando se habla de tecnologías audio/música. Doctor en teleco. Ha creado diversos dispositivos hard y soft y realizado programaciones para músicos y audiovisuales. Toca ocasionalmente en grupo por Madrid (teclados, claro).